Datentypen in Python
Inhalt
Das zweite Kapitel geht auf die von Python zur Verfügung gestellten Datentypen ein und deckt die folgenden Konzepte ab:
NoneType
Sequenzen
Details zu Zeichenketten
Listen
Tupel
Sets
Dictionaries
In Python unterscheidet man zwischen skalaren Datentypen und nicht-skalaren Datentypen (Objekte). Skalare Datentypen speichern lediglich eine bestimmte Art von Information, Objekte haben eine interne Struktur und stellen häufig auch Methoden zum Arbeiten mit den Daten zur Verfügung. Eine großer Vorteil von Python ist, dass die Sprache von Haus aus einige sehr mächtige Datentypen mitbringt. Dadurch lassen sich viele Probleme bereits ohne die Nutzung von zusätzlichen Bibliotheksfunktionen (Kapitel 5) lösen.
NoneType
Ein wichtiges, wenn auch nicht immer ganz intuitives Konzept, in der Programmierung sind Datentypen. In Java gibt es zum Beispiel null. In Python gibt es hierfür den NoneType der als einzigen möglichen Wert None hat. None wird zum Beispiel als Rückgabewert von Funktionen und Methoden benutzt, wenn es keinen “echten” Rückgabewert gibt, zum Beispiel weil etwas nicht gefunden wurde, oder weil es einfach keinen logischen Rückgabewert gibt. Der Rückgabewert der print() -Funktion ist zum Beispiel None. Um zu Überprüfen ob etwas None ist, benutzt ist is None. Um sicher zu gehen das etwas nicht None ist, nutzt man is not None.
>>> print(print("Hello World!") is None) Hello World! True >>> print(print("Hello World!") is not None) Hello World! False
Sequenzen
In Python spielen Sequenzen eine zentrale Rolle. Sequenzen sind, vereinfacht gesagt, Aneinanderreihungen von Objekten. Sequenzdatentypen sind alle Datentypen, die aus einer Aneinanderreihungen von Objekten bestehen. Dies können zum Beispiel Aneinanderreihungen von Zeichen sein um eine Zeichenkette zu bilden oder von beliebigen Objekten in einer Liste. Alle Sequenzen haben Gemeinsam, dass man über sie iterieren kann, dass heißt von einem Objekt zum nächsten gehen. Im folgenden Betrachten wir Zeichenketten als Sequenzen und führen mit Listen, Tupeln, und Sets noch weitere Sequenzen als Datentypen ein.
Details zu Zeichenketten
1. Indexzugriffe und Slicing
Bisher haben wir Zeichenketten immer als ganzes betrachtet. Man kann jedoch auch auf die einzelnen Zeichen zugreifen. Hierfür verwendet man Indexzugriffe, die in Python mit Hilfe von eckigen Klammern durchgeführt werden. Der Index des ersten Elements in Python is 0. Probiert man auf einen Index zuzugreifen, den es nicht gibt, bekommt man eine Fehlermeldung.
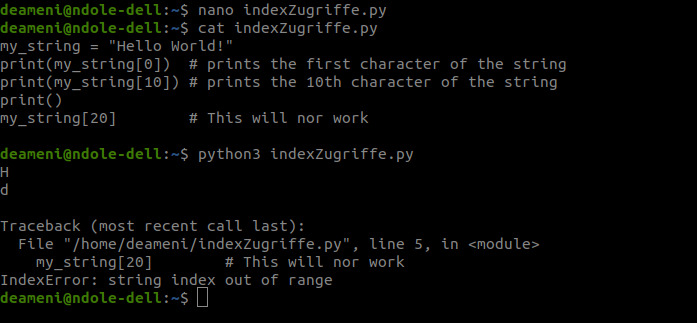 |
Man kann in Python auch negative Indizes verwenden. Hiermit greift man “von hinten” auf den String zu. -1 ist also das letzte Zeichen, -2 das vorletzte, etc.
>>> my_string = "Hello World!" >>> print(my_string[-1]) # prints the last character of the string ! >>> print(my_string[-10]) # prints the 10th character from the end of the string l
Für Zugriffe auf Teile von Zeichenketten gibt es das Konzept des slicing in Python. Hierzu wird der Doppelpunkt als Operator verwendet <start_index>:<end_index>. Der Startindex ist Teil des Slices (inclusive), der Endindex ist nicht Teil des Slices (exclusive). Lässt man den Start- oder Endindex weg, wird der Anfang, bzw. das Ende des Strings genommen. Die Länge einer Zeichenkette kann man mit len(string) bestimmen.
>>> my_string = "Hello World!" >>> # substring with the characters between index 0 (inclusive) and index 5 (exclusive) >>> print(my_string[0:5]) Hello >>> # substring with the characters between index 6 (inclusive) and index 11 (exclusive) >>> print(my_string[6:11]) World >>> # substring with the characters from the start of string until index 5 (exclusive) >>> print(my_string[:5]) Hello >>> # substring with the characters from index 6 (inclusive) until the end of the string >>> print(my_string[6:]) World! >>> # complete string >>> print(my_string[:]) Hello World! >>> print(len(my_string)) 12
Zeichenketten sind unveränderbar (immutable). Das bedeutet, das man eine bestehende Zeichenkette nicht direkt verändern kann. Probiert man es dennoch, bekommt man eine Fehlermeldung.
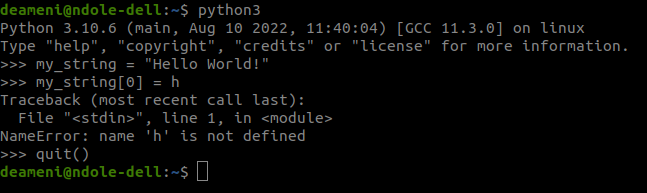 |
2. Formattierte Strings
Für Ausgaben ist es häufig wichtig Informationen in Zeichenketten aufzuarbeiten. In Kapitel 1 wir bereits gesehen, wie man durch Operatoren Zahlen und andere Strings aneinander anhängen kann. Auch wenn dies in einfachen Fällen ausreichend ist, stößt man schnell an die Grenzen, bzw. hat sehr viel Aufwand. Für “hübsche” formatierte Zeichenketten gibt es in Python verschiedene Möglichkeiten.
2.a) format()
In Python gibt es die Format Specification Mini-Language zur Definition von formatierten Zeichenketten. Hierzu wird die format() Methode von str benutzt. Durch geschweifte Klammern {} markierte Bereiche werden dann durch formatierte Strings von Objekten ersetzen.
>>> # format string with index >>> print("{0} = {1}".format("pi", 3.14159265359)) pi = 3.14159265359 >>> # same index can be used multiple times >>> print("{0} = {1} (approximation of {0})".format("pi", 3.14159265359)) pi = 3.14159265359 (approximation of pi) >>> # format string with names >>> print("{pi_str} = {pi_value}".format(pi_str="pi",pi_value=3.14159265359)) pi = 3.14159265359
Die Möglichkeiten von format() gehen weit über das reine einsetzen von Werten hinaus. Insbesondere lässt sich die Art, wie eine Zahl dargestellt werden soll, einstellen. Zum Beispiel lässt sich definieren, wie viele Nachkommastellen eine Zahl hat, wie Vorzeichen angezeigt werden, und ob eine wissenschaftliche Darstellung mit Hilfe eines Exponenten benutzt werden soll. Dies wird über eine Formatbeschreibung gemacht, die man mit einem : nach dem index, bzw. dem Namen des Parameters anhängt.
>>> # .2f specifies that three digits after the comma are displayed (rounded) >>> print("{0} = {1:.3f}".format("pi", 3.14159265359)) pi = 3.142 >>> # .5f specifies that five digits after the comma are displayed (rounded) >>> print("{0} = {1:.5f}".format("pi", 3.14159265359)) pi = 3.14159 >>> # specifies that scientific notation is used >>> print("{0:e}".format(10000000)) 1.000000e+07
2.b) Formattierte Stringliterale
Bei formattierter Stringliterale handelt es sich um “Zeichenketten mit Platzhaltern”. Hiermit ist es möglich die Werte von variablen dynamisch in Zeichenketten einzubetten. Man definiert, dass es sich um ein formattiertes Stringliteral, in dem man f (bzw. F) der Zeichenkette voran stellt. Durch geschweifte Klammern {} markiert man Bereiche, die durch Variablen ersetzt werden. Die Definition von Ersetzungen und der Formattierung ist die gleiche, wie bei format()).
>>> value = "World" >>> # formated string literal where {value} will be replaced by the content of the variable value >>> formated_string = f"Hello {value}!" >>> print(formated_string) Hello World!
2.c) printf-style Formatstrings
Python unterstützt auch formatierte Strings in einer ähnlichen Syntax wie man sie von printf aus der Sprache C kennt. Für diese Art formatierung hängt man die Objekte mit einem % an einen Zeichenkette an. Der Vorteil dieser Syntax ist, dass derartige Formatstrings weit verbreitet sind. Der Nachteil ist, dass man die Parameter weder benennen kann, noch über ihren Namen oder Index mehrfach verwenden kann.
>>> print("pi = %.3f" % 3.14159265359) # uses % notation in strings as is known from printf pi = 3.142 >>> print("%s = %.3f" % ("pi", 3.14159265359)) # use () in case mutliple objects are used pi = 3.142
3. Weitere wichtige Methoden für Strings
Zeichenketten in Python sind Objekte, das heißt es gibt Methoden, die direkt auf den Strings aufgerufen werden können um mit ihnen zu arbeiten. Hier sind einige Beispiele für hilfreiche Methoden. Eine vollständige Referenz finden Sie in der Python Dokumentation.
>>> my_string = "Hello World!" >>> # startswith tests if a string starts with another string >>> print(my_string.startswith("Hello")) True >>> # endswith tests if a string ends with another string >>> print(my_string.endswith("World")) False >>> # upper makes all characters upper case >>> print(my_string.upper()) HELLO WORLD! >>> # lower makes all characters lower case >>> print(my_string.lower()) hello world! >>> # rjust right-adjusts string by adding spaces (ljust also available) >>> print(my_string.rjust(30)) Hello World! >>> # strip removes all leading and trailing whitepaces >>> print(my_string.rjust(30).strip()) hello world! >>> # isnumeric checks if a string is a number (also available: isalpha, isalnum, isdigit, ...) >>> print(my_string.isnumeric()) False
Listen
Der Datentyp List speichert eine sortierte Sequenz von Objekten in Python. Listen werden mit Hilfe von eckigen Klammern definiert. Man kann auf jedes Element einer Liste mit Hilfe des Indexes und zugreifen, genau wie auf die einzelnen Zeichen von Zeichenketten, inklusive Zugriff durch Slicing. Die Anzahl der Elemente in einer Liste kann man mit len bestimmen.
>>> my_list = ["Hello","World","!"] >>> print(my_list) ['Hello', 'World', '!'] >>> print(my_list[0]) Hello >>> print(my_list[2]) ! >>> print(my_list[-1]) ! >>> print(my_list[-2]) World print(my_list[1:3]) ['World', '!'] >>> print(len(my_list)) 3
Will man wissen ob sich ein Objekt in einer Liste befindet, kann man den in Operator benutzen, um zu überprüfen ob ein Objekt sich nicht in einer Liste befindet nutzt man not in.
>>> print("Hello" in my_list) True >>> print("hi" not in my_list) True
Im Gegensatz zu Zeichenketten sind Listen veränderbar (mutable). Das heißt man kann Elemente durch andere Objekte ersetzen, sowie Elemente hinzufügen und entfernen. Zum Ersetzen kann man einfach per Indexzugriff neue Werte zuweisen. Zum Hinzufügen, beziehungsweise Entfernen von Elementen gibt es bei Listen die Methoden append(element) und insert(index, element), beziehungsweise remove(element) und pop(index). Man kann alle Elemente mit der clear() Mehtode entfernen. Einzelne Elemente können auch mit Hilfe von del und dem Indexzugriff gelöscht werden.
>>> my_changed_list = ["Hello","World","!"] >>> # changes the first element to "Hi" >>> my_changed_list[0] = "Hi" >>> print(my_changed_list) print(my_changed_list) >>> # appends a value at the end of the list >>> my_changed_list.append("!") >>> print(my_changed_list) ['Hi', 'World', '!', '!'] >>> # inserts a value at the given position of the list, all following elements move back >>> my_changed_list.insert(1,"beautiful") >>> print(my_changed_list) ['Hi', 'beautiful', 'World', '!', '!'] >>> # removes the first occurence of an element from a list >>> my_changed_list.remove("World") >>> print(my_changed_list) ['Hi', 'beautiful', '!', '!'] >>> # removes an element by using the index >>> my_changed_list.pop(1) >>> print(my_changed_list) ['Hi', 'beautiful', '!', '!'] >>> # removes an element with del >>> del my_changed_list[1] print(my_changed_list) ['Hi', '!'] >>> # removes all elements >>> my_changed_list.clear() >>> print(my_changed_list) []
Kommt das gleiche Element mehrfach in einer Liste vor, wird nur das erste dieser Elemente von remove entfernt. Da Listen verändert sind, reicht es nicht eine Liste einfach einer Variable zuzuweisen, um den aktuellen Zustand festzuhalten. Stattdessen muss man hierfür die copy() Methode benutzen.
>>> my_changed_list = ["Hello","World","!"] >>> my_other_reference = my_changed_list # assign the same list to another variable >>> my_copied_list = my_changed_list.copy() # create a copy of the list >>> my_changed_list[0] = "Hi" # modify my_changed_list >>> print(my_other_reference) # the reference is changed ['Hi', 'World', '!'] >>> print(my_copied_list) # the copy remains the same ['Hello', 'World', '!']
Bei der Kopie der Liste handelt es sich um eine shallow copy, das heißt es wird lediglich die Liste kopiert, die Elemente der Liste werden nicht ebenfalls kopiert. (Mehr zum Kopieren gibt es in Kapitel 7.)
Weitere Methoden zum Arbeiten mit Listen sind sort() zum Sortieren der Werte, reverse() um die Reihenfolge der Listenelemente zu invertieren, und count(element) um zu Zählen wie häufig ein Element in einer Liste vorkommt.
Tupel
Das leere Tupel kann man einfach durch leere Klammern () erstellen. Einelementige Tupel sind jedoch Syntaktisch etwas unschön, da es nicht ausreicht einfach ein Objekt in Klammern zu setzen. Man braucht zusätzlich noch ein Komma am Ende.
>>> no_tuple = ("hello") >>> print(type(no_tuple)) <class 'str'> >>> one_element_tuple = ("hello",) >>> print(type(one_element_tuple)) <class 'tuple'> >>> print(len(one_element_tuple)) 1
Vereinfacht gesagt, können mit dem Datentyp tuple unveränderliche Listen erstellt werden. Die Erstellung von Tupeln ist ähnlich wie das Erstellen von Listen, nur das () genutzt wird.
>>> my_tuple = ("Hello", "World", "!") # creates a new tuple >>> print(my_tuple) ('Hello', 'World', '!') >>> print(my_tuple[1]) World >>> print("Hello" in my_tuple) True >>> print("Hi" not in my_tuple) True >>> print(len(my_tuple)) 3
Eine wichtige Eigentschaft von Tupeln ist das packing, bzw. das unpacking. Das packing ist vergleichbar zu Mehrfachzuweisungen, nur dass statt mehreren Variablen nur ein Tupel zugewiesen wird. Beim unpacking passiert das Gegenteil: aus einem Tupel werden mehrere Variablen zugewiesen. Beim unpacking muss man beachten, dass die Anzahl der zugewiesen Variablen der Länge des Tupels entsprechen muss, also jeder Wert im Tupel muss einer Variablen zugewiesen werden. Ansonsten gibt es eine Fehlermeldung.
>>> # creates a tuple through packing, only works with tuples >>> my_tuple = "Hello","World","!" >>> print(my_tuple) ('Hello', 'World', '!') >>> # unpacks the tuple into three variables, also works with lists >>> hello,world,exclamation = my_tuple >>> print(hello) Hello >>> print(world) World >>> print(exclamation) !
Sets
Sowohl Listen als auch Tuple können das selbe Objekt mehrfach beinhalten. Mengen haben die Eigenschaft, dass sie jedes Objekt nur einmal enthalten, und im Gegenzug werden sie nicht sortiert, wenn man nicht explizit danach fragt. In Python gibt es hierfür den Datentyp set. Um eine Menge zu definieren benutzt man entweder set() oder geschweifte Klammern {}.
>>> # creates a new set >>> my_set = {"Hello", "Hello", "World", "!"} >>> # same as above, but creates the set from a list >>> my_set = set(["Hello", "Hello", "World", "!"]) >>> print(my_set) {'Hello', 'World', '!'} >>> print("Hello" in my_set) True >>> print("hi" not in my_set) True >>> print(len(my_set)) 3
Sets sind, genau wie Listen, veränderbar. Objekte können mit add(element) hinzugefügt und mit remove(element), bzw. discard(element) entfernt werden. Der unterschied zwischen remove und discard ist, dass es bei remove einen Fehler gibt, wenn es das Objekt nicht in der Menge gibt. Man kann alle Elemente mit clear() entfernen.
>>> my_changing_set = {"Hello", "World", "!"} >>> my_changing_set.add("hi") # adds "hi" to the set >>> my_changing_set.add("hi") # does nothing, "hi" already part of the set >>> print(my_changing_set) {'Hello', 'hi', 'World', '!'} >>> my_changing_set.remove("Hello") # removes "Hello" from the set >>> print(my_changing_set) {'hi', 'World', '!'} >>> my_changing_set.clear() set()
Da es sich bei beim Datentyp set um Mengen im Sinne der mathematischen Definition von Mengen handelt, kann man auch Mengenoperationen durchführen. Verfügbar sind die Vereinigung (union), Schnittmenge (difference), Differenzmenge (intersection) und die symmetrische Differenz (symmetric_difference). Außerdem kann man überprüfen ob es sich um eine Teilmenge (issubset) oder eine Obermenge (issuperset) handelt, sowie ob Mengen disjunkt sind (isdisjunct).
>>> set1 = {1, 2, 3, 4} >>> set2 = {3, 4, 5, 6} >>> print(set1.union(set2)) {1, 2, 3, 4, 5, 6} >>> print(set1.intersection(set2)) {3, 4} >>> print(set1.difference(set2)) {1, 2} >>> print(set1.symmetric_difference(set2)) {1, 2, 5, 6} >>> print(set1.issubset(set2)) False >>> print(set1.issuperset(set2)) False >>> print(set1.isdisjoint(set2)) False
Für die meisten Mengenoperatiotionen gibt es auch Operatoren, die man direkt verwenden kann. Hierzu wurde die Ähnlichkeit von Mengenoperationen mit logischen arithmetrischen Operationen genutzt.
>>> set1 = {1, 2, 3, 4} >>> set2 = {3, 4, 5, 6} >>> print(set1 | set2) # union because of similarity to a logical or {1, 2, 3, 4, 5, 6} >>> print(set1 & set2) # intersection because of similarity to a logical not {3, 4} >>> print(set1 - set2) # difference because of similarity to an arithmetic minus {1, 2} >>> print(set1 ^ set2) # symmetric_difference because of the similarity to a logical xor {1, 2, 5, 6} >>> print(set1 <= set2) # issubset because of the similarity to less than or equal too False >>> print(set1 >= set2) # issuperset because of the similartiy to greater than or equal too False
Dictionaries
Bei Dictionaries handelt es sich um einen Datentypen dict der Abbildungen von Schlüsseln (key) auf Werte (value) verwaltet. Zu jedem Schlüssel, kann es nur einen Wert geben. Dictionaries werden, ähnlich wie Mengen, mit Hilfe von {} definiert. Im Unterschied zu Mengen, müssen Key-Value Paare in der Form <key>:<value> oder als Tupel (key,value) angegeben werden. Der Zugriff auf Elemente in Dictionaries erfolgt ähnlich zum Zugriff auf Elemente von Listen mit Hilfe von , nur dass statt dem Index der Schlüssel verwendet wird. Da Dictionaries veränderbar sind, kann man auf diese Art auch neue Key-Value Paare in einem Dict hinzufügen, bzw. bestehende Einträge aktualisieren. Probiert man auf einen Schlüssel zuzugreifen, den es in dem Dictionary nicht gibt, gibt es eine Fehlermeldung
>>> my_dict = {"pi": 3.14159265359, "c": 299792458} >>> print(my_dict) {'pi': 3.14159265359, 'c': 299792458} >>> print(my_dict["pi"]) 3.14159265359 >>> print(my_dict["c"]) 299792458 >>> my_dict["e"] = 1.602e-19 >>> my_dict["pi"] = 3.14 >>> print(my_dict) {'pi': 3.14, 'c': 299792458, 'e': 1.602e-19} >>> print("pi" in my_dict) True >>> print("mu0" not in my_dict) True >>> print(len(my_dict)) 3
Mit Hilfe der Methoden items(), keys() und values() bekommt man einen View auf alle Key-Value Paare als Tupel, alle Schlüssel, beziehungsweise alle Werte. Aus einem View kann man zum Beispiel eine Liste erstellen oder über die Elemente mit einer Schleife iterieren (siehe Kapitel 3). Views sind dynamisch, das heißt sie Spiegeln immer den aktuellen Zustand des Dictionaries wieder.
>>> key_view = my_dict.keys() >>> print(key_view) dict_keys(['pi', 'c', 'e']) >>> print(list(key_view)) ['pi', 'c', 'e'] >>> my_dict["h"] = 6.626e-34 >>> print(key_view) dict_keys(['pi', 'c', 'e', 'h'])
Mit Hilfe der pop(key, default) Methode kann man Elemente aus einem Dict entfernen. Die Methode hat den Wert des Entfernten Key-Value Paars als Rückgabewert. Ist kein Eintrag zu dem Schlüssel im Dict vorhanden, wird der im default Parameter angegebene Wert zurück gegeben. Man nutzt None als default, wenn man Schlüssel entfernen möchte, bei denen man nicht sicher ist, ob diese existieren. Der default Parameter von pop ist optional. Lässt man ihn weg, gibt es eine Fehlermeldung, wenn ein Schlüssel nicht existiert.
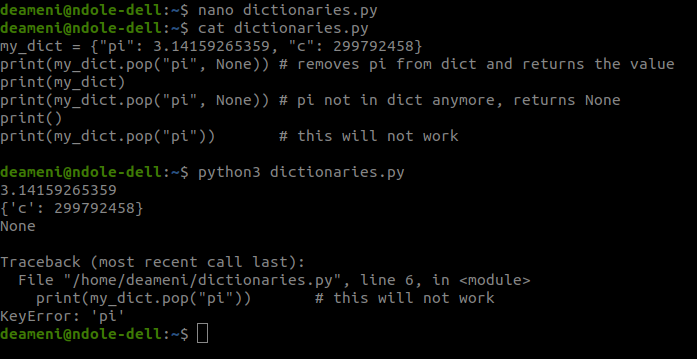 |
Man kann auch del benutzen um Elemente aus einem Dictionary zu löschen. Da man jedoch keinen Default angeben kann, ist pop in der Regel die bessere Variante.